
Speech recognition is currently the most mature human-computer interaction method. From near-field speech recognition, such as Siri, and various voice assistants, which have been experienced by people at the beginning, we have already completed the application of speech recognition. Intelligent hardware and robots are extended. However, new human-computer interactions require more stringent hardware and algorithm requirements. Companies are facing enormous challenges.
What problems need to be solved to achieve human-computer interaction? Which of these key technologies are there? What is the future trend of human-computer interaction? In this month's hard-to-get open class, Yanyan Jun, the R&D director of HKUST, was asked to answer questions.

Sharing guests: Zhao Yanjun, Director of AIUI project, Head of R&D of Feiyun Platform of HKUST, responsible for the development of a number of products such as Open-Fee Voice Recognition, Speech Synthesis, Voiceprint, and Wake-up, as well as the development of AIUI, a human-computer interaction solution. Committed to better productization of core technologies, making people's communication with machines as simple and natural as people.
Human-computer interaction pain pointsAs the main method of human-computer interaction at present, voice should be able to cite some examples if everyone has used it. For example, speaking near, pronunciation should be standard, the environment should be quiet, conversation can not be sustained, and can not be interrupted.

Not only speech, including images, obstacle detection and other technologies, will encounter such problems, such as face recognition, there are certain requirements for light, angle, distance. To sum up, one point is that there are still many problems that need to be solved in the current adaptation of human-computer interaction in complex environments. This is only a perceptual level. It also includes a cognitive level. AI is not as smart as we currently think. At present, it cannot fully autonomously learn. It still requires human intervention, such as the introduction of a knowledge base and the correction of machine behavior. Participation.
In the current human-computer interaction products, when faced with users, the robustness is not good enough in the face of complex environments. Today's sharing, we discuss together how to solve these problems, whether through algorithms, engineering, or products, are all ways we can choose.
First of all, we must have a consensus that the problems currently faced by human-computer interaction are not resolved overnight and can be solved overnight. We need to make constant progress in core technologies in all directions.
How does the HKUST fly AIUI?
AIUI is a human-computer intelligent interactive interface designed to realize the barrier-free interaction between humans and machines and enables human-machine interactions, like human beings, to continue through natural interactions such as voice, images, and gestures. Bidirectional, communicate naturally. It consists of a combination of cloud and client-based service frameworks, including audio and video front-end signal processing, cloud + end-to-end interaction engine, content and knowledge platform and interface, user personalization system. The platform is open, and third parties can perform flexible configuration, business expansion, and content matching.
Previous voice interactive products, including Xunfei, provided us with a single point of capability, such as speech synthesis, speech arousal, speech recognition, semantic understanding, as well as face recognition and voiceprint recognition. With so many products and capabilities, it takes a lot of work to develop human-computer interaction.
The problem is more obvious in this way:
On the one hand, the workload of product integration is too large, which has caused many small and medium-sized developers to be unable to undertake this part of the workload;
In addition, because the interaction process is too long and the details are not handled properly, the interaction experience of products is uneven.
Therefore, the AIUI interaction program must first solve this problem. AIUI is a system that integrates microphone array, front-end acoustic processing, voice wake-up, endpoint detection, speech recognition, semantic understanding, and speech synthesis on the entire interaction chain.
And AIUI also supports new features such as full-duplex and multi-round interaction, and breakthroughs and evolutions in single-point technology, including sound source location and tracking, continuous online, effective human voice intelligent detection, and dynamic voice endpoint based on user's intentions. Detection, support for semantic understanding of contextual interactions, speech recognition based on dialogue scene adaptation, etc.
Popular Science: The process of voice interaction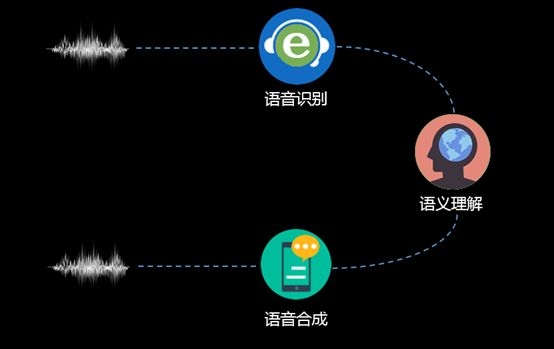
First of all, human-machine voice interactions (here mainly referred to as smart hardware, robots, etc.) are different from traditional hand-held handheld devices. In traditional voice interactions, because they are near-field, the voice signal quality is relatively high, and there are Touch screen assistance, so interactive links can be relatively simple. By clicking on the screen to trigger, and then by clicking on the screen or energy VAD detection, to end the speech signal acquisition, you can complete an interaction, the entire process can be completed through speech recognition, semantic understanding, speech synthesis.
For human-machine interactions, due to the far-field, the environment is more complex and there is no screen interaction. If you want to be as natural, continuous, two-way, and interruptable as human-to-human communication, the entire interaction process needs to be resolved. The problem is more, AIUI is to complete the human voice interaction, is a process that requires hardware and software integration, cloud + end cooperation.
Let's take a look at the entire process of interaction. From a large perspective, we still use speech recognition, semantic understanding, and speech synthesis as the main line, but each process needs to solve more problems.
First of all, let's take a look at the wake-up of speech . Awakening is the main trigger for human-computer interaction. Just like you have to talk to a person, you must first call the person's name before you can start communicating. In the process of communication, if someone else calls you, you also need to respond and need to support continued awakening.
After the machine is awakened, it needs to know the speaker's position so that the machine can make a more friendly response, such as turning, moving and so on. Only after clarifying the position of the speaker can the targeted sound pickup be done, noise reduction processing can be performed, and the speaker can perform speech enhancement at the same time. This sound source localization and speech enhancement is mainly related to the microphone array technology, which will be explained in detail below.
In the important module of speech recognition, the first thing to be solved is far-field recognition. Through the microphone array and sound source positioning mentioned above, it is possible to achieve long-distance sound pickup and solve the effects of noise, reverberation, and echo. . As a full-duplex interaction, continuous audio stream picking, it is necessary to solve the problem of vocal detection and segmentation. The machine needs to be able to filter invalid speech and make quick feedback and response.
The detection of vocals and endpoints cannot rely solely on energy detection technology solutions. It needs to solve more complex environments. How to solve them?
For recognition, the first thing to be guaranteed is the recognition rate in the far-field environment. In addition to the previously mentioned microphone array that solves the problem of front-end acoustics, there is also an acoustic model that is based on massive data training specifically for the far-field environment. This can ensure that the recognition rate meets the interactive requirements.
In addition to voice recognition in the cloud, end-to-end identification needs to be done as well. Cloud-based and end-to-end methods are required to be combined to meet the usage scenarios of complex networks. However, the port is mainly to do some imperative interaction in response to some local operations. Such as shut down, call, action instructions.
The local is not made unlimited response, because for many user intentions, it is necessary to obtain content based on the network, so the only auxiliary use of the local, is to solve some complex network environment to do the means. The difficulty in this place is the need to do a cloud and end PK strategy, and it is necessary to make comprehensive decisions based on confidence, response time and other information. As a continuous voice interaction, it is inevitable to absorb a lot of invalid speech, and rejection becomes a necessity, otherwise it will cause confusion and non-meaningful response to the dialogue.
For multiple rounds of interactive understanding, the semantic engine is no longer stateless, and the system is more complex and requires modules such as dialog management and historical information storage. Semantic comprehension not only includes user's speech intent, but also includes content acquisition. In this way, information can be shared during the subsequent endpoint detection, speech recognition, and other interactive processes, so that the scene can be self-adaptive so as to improve the accuracy.
After completing the speech recognition and semantic understanding, the machine needs to pass the speech synthesis to deliver the information to the user. There is not much need for the synthesis of this piece, and Information Flight has provided dozens of different types of speakers, but also supports reading with different emotions. As for what kind of situations and emotions to broadcast, this is needed in semantic understanding. information. Compared to traditional interactions, the current process can look a lot more complicated.
Function: Far-field recognition, full-duplex, multi-round interactive far-field recognition
Far-field recognition requires front-end and back-end combining. On the one hand, microphone array hardware is used at the front end, and speech enhancement is performed through sound source localization and adaptive beamforming. The far-field pickup is completed at the front end, and the effects of noise, reverberation, and echo are resolved.
However, this is not enough, because the near-field, far-field voice signal, there are some differences in the acoustics, so in the back-end speech recognition, you need to combine the acoustic model based on big data training, for the far-field environment, in order to Better solve the problem of recognition rate.
Full duplex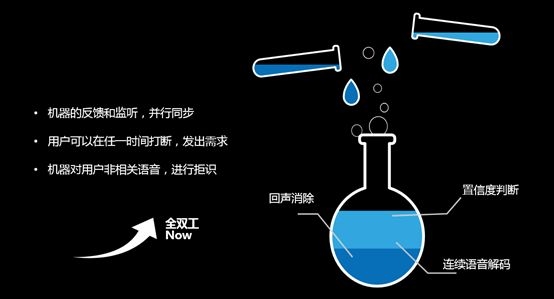
Full-duplex interaction is a full link penetration process, not only continuous pickup and network transmission, but also includes continuous voice wakeup, intelligent and effective voice detection, dynamic voice endpoint detection, and invalid voice rejection. Mutual cooperation can be accomplished.
Supporting continuous speech wake-up is a must. In the traditional speech awakening scheme, after a wake-up, speech recognition and interaction are performed, and the interaction is completed and the state to be awakened is entered again. However, in actual person-to-person communication, people can talk to many people, and they can be inserted and interrupted by others. Voice wakeup in AIUI uses BN (Bottle Neck) technology solution to support low-power standby.
Full-duplex interaction as a continuous interactive process, speech recognition and semantic understanding needs to be able to make a quick response. This requires vocal detection and intelligent segmentation. The traditional segmentation is based on the detection of energy, but there are two main drawbacks. First, it is impossible to filter noise and invalid speech. In addition, the speaker is more demanding and there can be no pause in the middle. If the rear end point is set too short, it will cause truncation; if the rear end point is too long, it will cause the response not to be timely.
AIUI's approach is to use model-based effective vocal intelligence detection and dynamic speech endpoint detection based on user intent. Model-based detection can effectively solve noise and invalid speech. This block mainly collects the noise of different environments, and based on the deep neural network training out the corresponding acoustic model, filtering, and effective voice transmission to the cloud for interaction.
The dynamic endpoint detection algorithm realizes that the speech input semantics understanding module containing the complete user intention is detected from the continuously input data stream, and the user's pause can be well resolved because in the human-machine interaction process, one sentence contains the complete intention voice Pause is a very common phenomenon, which is verified in our analysis of user behavior.
In addition, in the process of continuous voice interaction, there must be invalid speech and unrelated speech content is absorbed, so rejection is necessary. In the AIUI system, we have specially constructed a set of rejection system based on deep neural networks for this problem in full-duplex interaction, and reject the received speech from many aspects such as acoustic signals and semantics.
Multiple rounds of interaction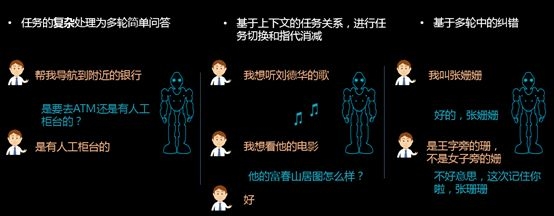
In the same way, for the two modules of semantic understanding and dialogue management in multiple rounds of interactions, we also use deep learning + mass data, using the actual data of users, to train robust semantic understanding and dialogue management models.
Combine the LSTM (long-short-term memory) based circulatory neural network to make the model have the ability of long-term memory, and use the context of conversation to perform accurate semantic understanding. I believe that the combination of TUTM (long-short-term memory) circulatory neural network + deep data + big data + “flaw effect†research ideas Our multiple rounds of interactions will become more accurate and useful.
Key Technology: Microphone Array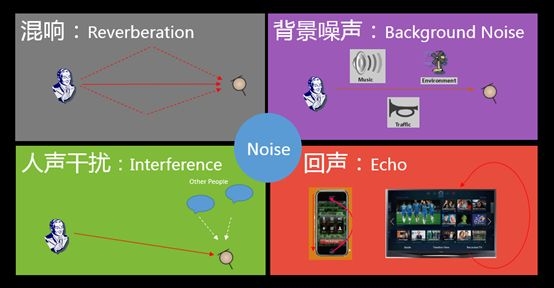
As we can see from the above figure, factors such as noise, reverberation, vocal disturbances and echoes in the real environment are still relatively large, and we generally solve it by using a microphone array.
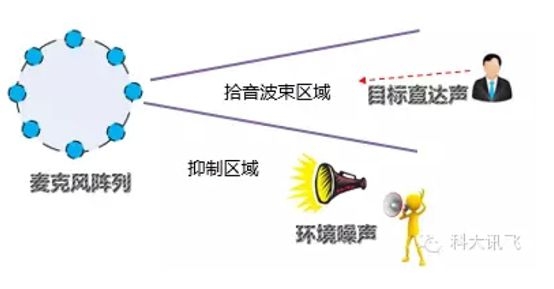
A microphone array is a system that uses a certain number of spatial sensors (usually microphones) to sample and process the spatial characteristics of the sound field. The microphone array can do a lot of things. For ambient noise, it can use adaptive beamforming to perform speech enhancement and extract pure speech from a noisy speech signal. For speaker's speech position inaccuracy, it can be used by sound source localization technology. Calculate the target speaker's angle to track the speaker and follow-up voice directional pickup; for indoor sound reflection, resulting in overlap of the voice phoneme, the problem of low recognition rate, it can reduce the reverberation by de-reverberation technology. Recognition rate.
The linear, ring, and spherical microphones are not much different in principle, but due to the different spatial configurations, the spatial range in which they can be resolved is also different. For example, in sound source localization, the linear array has only one-dimensional information and can only distinguish 180 degrees. The annular array is a planar array and has two-dimensional information and can resolve 360 ​​degrees. The spherical array is a three-dimensional spatial array and has three-dimensional information. Can distinguish between 360 degree azimuth and 180 degree pitch angle.
Second, the greater the number of microphones, the higher the positioning accuracy of the speaker , but the difference in positioning accuracy is reflected in the distance of the interaction distance. If the interaction distance is not very far, the positioning effect of 5 wheat and 8 wheat is not very different. In addition, the greater the number of microphones, the finer the space that can be distinguished by the beam, and the higher the quality of sound pickup in a noisy environment. However, under the quiet environment of a typical indoor environment, the difference between the recognition rates of 5 and 8 wheat is not large. The more the number of microphones, the higher the cost, the specific product, to consider the application scenario and the actual product positioning, select the appropriate number of microphones and formation.
Scenario: Exploring the Impact of Environment on Speech Recognition
The complex environment, on the one hand, is the complexity of the external environment, and on the other hand, it is dialects and accents. The external environment is complex, including noise, reverberation, and echo, and the noise is divided into different environments such as different meeting rooms, outdoor areas, and shopping malls. In order to solve these problems, in addition to the single-channel voice enhancement technology, the above mentioned is basically adopted. Microphone array hardware and related algorithm implementations.
In terms of dialects and accents, we all know that in our country, dozens of dialects and individuals all have their own unique accents. The general solution is based on various dialect data. Through deep neural networks, various dialect models are trained. To increase the recognition rate, this is a common practice in the industry.
In order to solve the two problems, Information Technology is adapting to the requirements of various complex environments through the following technical solutions. Includes the following:
1) Provide a variety of different microphone array configurations, such as bar, ring, and spherical four wheat, five wheat, eight wheat and so on, to adapt to different product needs, such as the ring speaker is used in the ring 8M.
Although the microphone array technology has reached a considerable technical level, there are still some problems in general, such as when the microphone and the signal source are too far away (such as 10m, 20m distance), the signal to noise ratio of the recorded signal will be very low, the algorithm Processing is very difficult; for portable devices, due to device size and power consumption, the number of microphones cannot be too large and the array size cannot be too large. Distributed microphone array technology is a possible way to solve current problems.
The so-called distributed array is to dispose sub-elements or sub-arrays to a wider range, exchange or share data with each other through wired or wireless methods, and perform sound source positioning and beam broadening on this basis. Forming and other technologies to achieve signal processing.
Compared to the current centralized microphone arrays, the advantages of distributed arrays are also very obvious. First of all, the size limit of the distributed microphone array (especially wireless transmission) does not exist; in addition, the nodes of the array can cover a large area. There will always be an array of nodes close to the sound source, recording signal to noise ratio is greatly improved, the difficulty of the algorithm processing will be reduced, the overall effect of signal processing will also have a very significant improvement, the current HKUST news has begun related Technical research layout work.
2) Acoustic models for speech recognition in different environments, such as far-field pickup as mentioned above, which are specially designed for long distance pickup environments;
3) In terms of dialects, XFEI supports more than 20 dialects, including Putonghua and Cantonese, which are currently the most widely used dialects. Accumulated a certain amount of multi-dialect resource pool, and based on the special deep neural network structure and semi-supervised training of on-line data, the multi-dialect data information sharing and automatic iterative updating of dialects are realized.
The biggest difficulty in other dialects lies in the self-adaptation of dialects. How can we automatically match models based on the user's voice?
4) In terms of adaption of accents, Newsflash already has a complete user-based training system, which can be used to create a closed-loop optimization process for each user, and create a personalized acoustic model for each user. Input method pilot, for some registered users to grayscale reflect;
5) Based on model training for specific groups of people, it is currently a children-oriented toy program that specifically trains acoustic matching models for children;
6) Provide a personalized language model for each application, each user;
AIUI services
AIUI is completely open to the outside world, whether it is an individual developer or a company, and it can be used on our platform. Since AIUI needs to be combined with hardware, it is now open in the form of an evaluation board. If the evaluation results meet product requirements, we provide modules or soft cores to support product volume production.
In addition to providing an overall solution and dozens of business scenarios, the open platform also provides product customization capabilities, including awakening word customization, speaker customization, interaction semantics customization, speech recognition resource customization, and process parameter configuration. It is a function that is open on the Web platform. Developers can personalize configuration and editing on the platform according to product requirements.
Such as the semantic open platform, providing private semantics writing, custom question and answer import, this one is believed to be the most concerned, how each robot answers the user's question, mainly through this aspect.
It is also very important that AIUI allows third-party systems to access AIUI as an extensible scaling service. After recognition and semantic results of voice cloud processing, the third-party service system can be accessed through the Http service as long as it is configured on the platform. To meet more complex individual needs.
Of course, the information flight open platform also provides in-depth customized services, including awakening word training, pronunciation training, semantics and content production. Through platform opening and deep customization, the difference between products can be satisfied.
Future: Human-computer interaction will converge?Fusion must be the trend of human-computer interaction in the future.
Taking AIUI as an example, at the beginning of definition, we did not regard speech as the only interaction method, but instead envisaged it as a human-computer interaction solution that integrates human face, body tracking, gestures, and infrared.
We are also constantly trying to combine voice and other methods. For example, we are now on the line face, voice pattern fusion authentication, which is the most direct example, in this way will be able to effectively solve the user's identity authentication.
In AIUI, there are also many scenarios that need to work together in different ways. For example, in the AIUI, in order to solve the continuous interaction in the far field, a microphone array is used and directional pickup is used to solve this problem, but due to the limited angle of the directional pickup, the continuous interaction process causes the speaker to Mobile becomes a problem. At this time, mobile sources need to be located and tracked. Simply relying on the identification and tracking of sounds, it is difficult to effectively solve this problem. This time, if it can be combined with human tracking, such as images and infrared, it will be able to Further reduce the probability of error. Other scenes include people's age, gender, and other attributes. If images and sounds are combined, the accuracy will be greatly improved and the machine's perception ability will be improved. AI will also be more intelligent.
(If you are interested in the AIUI of HKUST, you can click AIUI to see the details.)
Outdoor Fixed Advertising LED Video Wall
This series is professionally used for Waterproof Outdoor fixed installation of advertising LED Screen, a variety of installation solutions such as wall installation, shelf installation, photo frame installation and so on. Outdoor Fixed Advertising LED Video Wall Displays advertising video content well outdoors. It is suitable for Shopping mall, outside building, School, Shops, Side road...Strong waterproof Iron cabinet design, seamless connection to realize large-screen display advertisement, high-definition smooth video playback function.

Outdoor Fixed Advertising Video Wall,Outdoor Fixed Led Billboards Waterproof,Outdoor Display Advertising,Outdoor Movie Screen Rental
Guangzhou Cheng Wen Photoelectric Technology Co., Ltd. , https://www.leddisplaycw.com