
Artificial intelligence is very hot, but the foam is also very large. The application of artificial intelligence in the video field has entered the life of ordinary people. Face recognition and video automatic keying technology have been relatively mature. In addition, what changes can artificial intelligence bring to video applications? Describes the practical exploration of artificial intelligence in video applications, involving codecs, super-resolution, and so on.
Preface: Artificial Intelligence Comes to the Present
Artificial intelligence is a very broad field, and current artificial intelligence covers many large disciplines, roughly summarized into six:
Computer vision (for example, the problem of pattern recognition, image processing, etc.);
Natural language understanding and communication (for the time being, speech recognition and synthesis are included, including dialogue);
Cognition and reasoning (including various physical and social common sense);
Robotics (mechanical, control, design, motion planning, mission planning, etc.);
Game and ethics (interaction, confrontation and cooperation of multi-agent agents, robotics and social integration issues);
Machine learning (various statistical modeling, analysis tools, and computational methods).
Here are a few points worth highlighting:
First, the current artificial intelligence is a range of weak artificial intelligence, which exists as a tool used by humans in a certain professional field. At present, there is no artificial intelligence that runs away from the human subject, and there is no strong artificial intelligence that can develop artificial intelligence self-iterative evolution.
Second, machine learning has made great progress in recent years. Some people directly regard machine learning as synonymous with artificial intelligence. This is not accurate. For example, it is undeniable that machine learning plays an increasingly important role in the field of computer vision. However, in the traditional sense, pattern recognition, image recognition and image enhancement obtained through manual modeling are still very successful artificial intelligence technologies. And is also the basis for the further development of machine learning.
Third, statistical analysis methods emerged in the 1990s and were used in certain areas. There are also a variety of statistical analysis methods, and many successful cases have been generated according to actual needs, and the current standard modeling and analysis methods are not necessarily used. Here is a typical example. Before Intel introduced the mmx technology in 1997, programmers circulated a very well-known lookup table IDCT (anti-cosine transform), which is actually the IDCT transform of the MPEG1 codec process. After the analysis, it was found that it exceeded the actual combat cases of all the fast algorithms. For details, please click "Read the original" to download IDCT 8x8.DOC.
Fourth) Machine learning has these obvious defects. If you want to achieve good results in actual combat, you must make reasonable trade-offs and optimizations. These few defects are:
Seriously dependent on data, training methods and training volume are critical.
The amount of calculation is too high.
Although sometimes good results have been achieved, machine learning itself does not understand the process and does not give a reasonable explanation.
Involving the problems of natural science common sense and social science common sense, machine learning can not achieve good results in the open field.
(1) Infiltration of artificial intelligence into video applications
The process of traditional video applications:

As we said before, the current artificial intelligence is still in the tool stage, that is to say, there is no coding method, transmission protocol, decoding and interaction technology beyond the era developed by artificial intelligence. At present, artificial intelligence penetration includes pre-processing and post-processing, super-resolution, machine vision, etc., and people use artificial intelligence tools to improve development efficiency or processing effects in these processes. The codec technology is a problem that can be solved by the human expert technical team. The current artificial intelligence is difficult to intervene.

In recent years, the rise of webcasting applications has seen a demand that is different from previous broadcast TV codecs. That is:
The encoding end guarantees the real-time and code rate requirements of the encoding while ensuring the highest possible image quality.
Send, transmit, buffer, and delay as small as possible.
The decoder can output the best quality possible, preferably super resolution.
In the past two years, I have been working hard to integrate artificial intelligence (mainly machine learning) technology with codec to solve these problems that traditional methods have been difficult to solve.
Problems encountered with the encoder: The hardware encoder performs well, but the image quality is poor and the code rate is high. Software encoders are inefficient, encounter complex video, such as a large number of objects, large motion, flash, and rotation, which can not meet the needs of real-time encoding, and the output bit rate also has large jitter. It is a big obstacle for web applications.
The decoder needs to be enhanced: everyone is thinking about whether you can apply super-resolution technology and improve the playback quality of lower-resolution video. There are a lot of algorithms that show great potential, such as Google's RAISR, which works well when dealing with images. Can you use the video in real time, or hardware, or use a faster algorithm that can run in real time. We will discuss a compromise solution in the future, a super-resolution algorithm that can run in real time at the expense of a bit of quality.
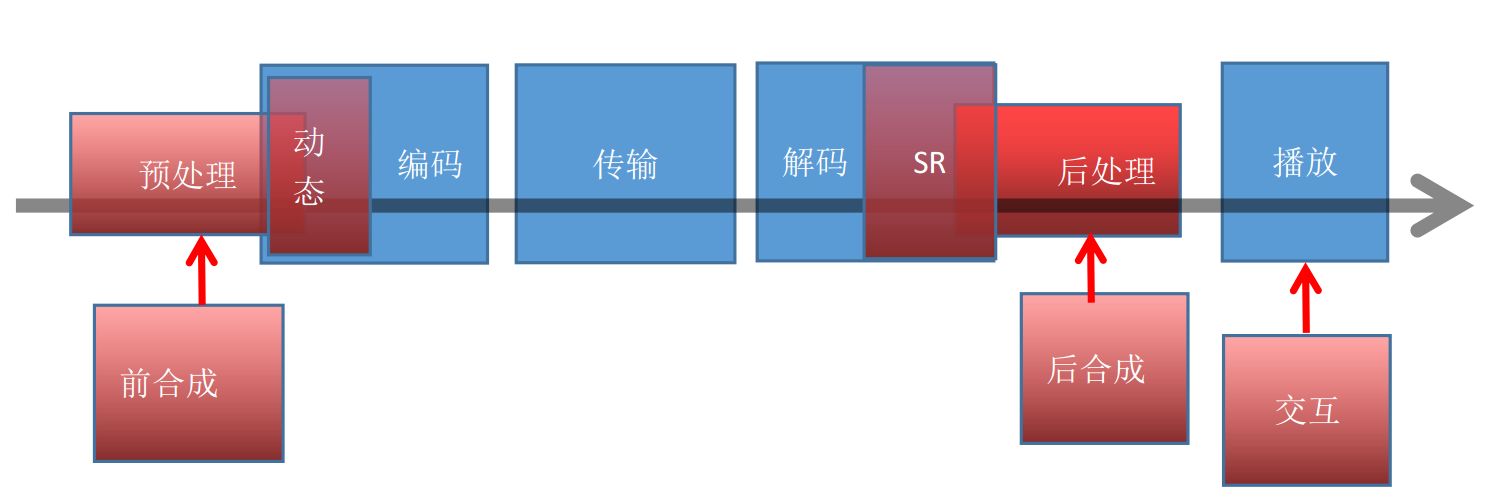
(2) Artificial intelligence enhanced encoder
(2.1) Dynamic Encoder
The code rate at which the code maintains a constant quality in different scenarios:
The coding time and the code rate are positively correlated, and the coding time is also greatly prolonged while the code rate is skyrocketing. For live broadcast applications with low latency requirements, it can cause serious jams.
Generally, we have to use the absolute constant rate ABR. The image quality of ABR in different scenarios:
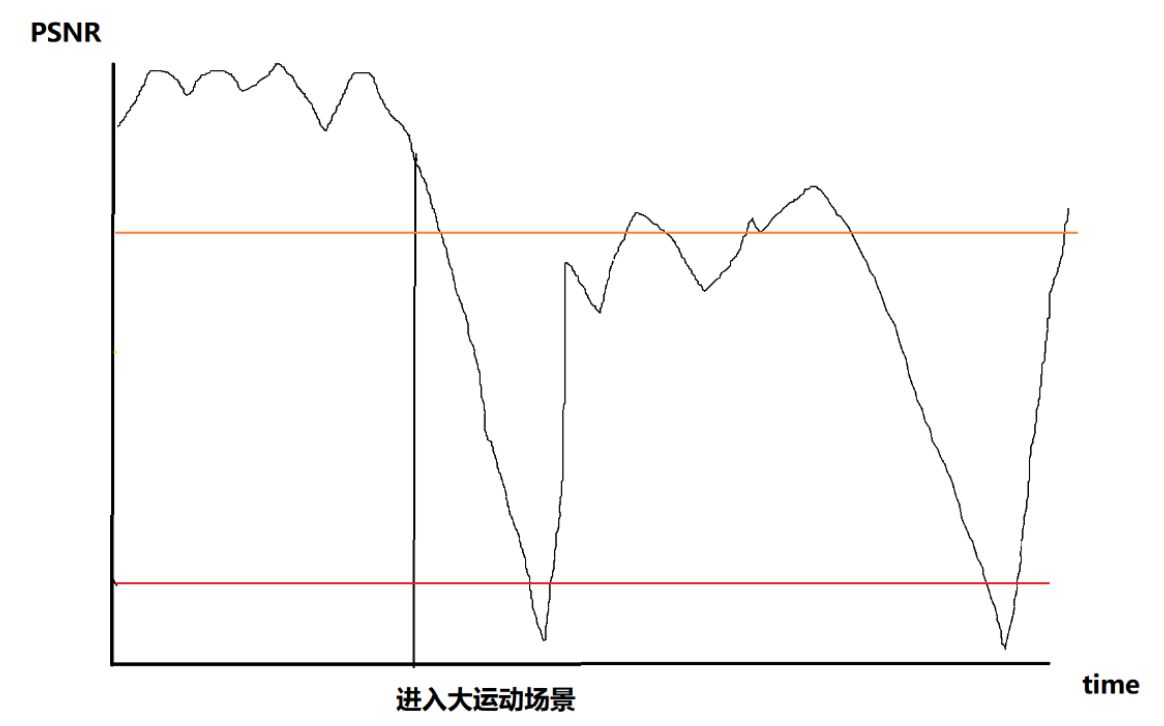
The result of this is that the image quality is unstable.
We hope that this is the curve like this:
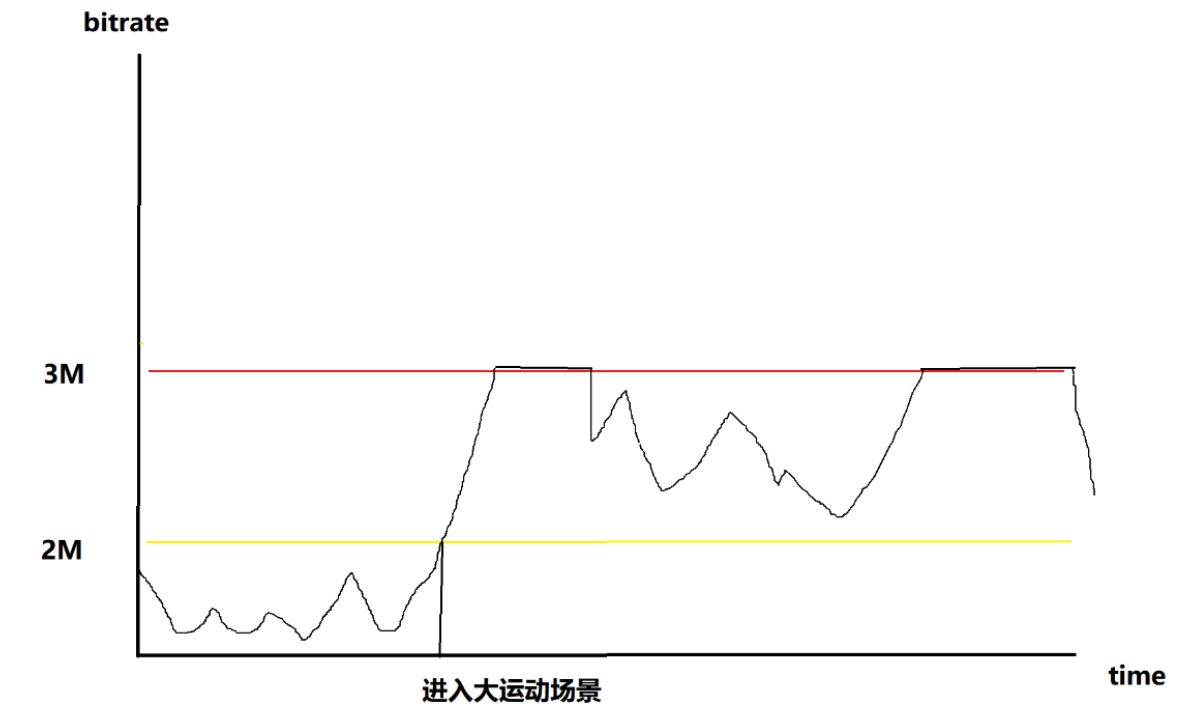
This requires the encoder to determine in advance the possibility of a large rate scene. Several situations that need to be determined:
There are many objects and there is camera movement.
The background does not move but there are a large range of motions of a large number of objects, including fast motion, rotation, affine, creep, and the like.
Flash, sand, particle system.
This requires the development of a scene-oriented intelligent coding technique for high definition live broadcast applications. The technology classifies and quickly identifies common video coding Kardon scenes by supervised learning, predicts the coding complexity and rate jitter of the video scene in advance, and uses dynamic parameter configuration to encode, ensuring the real-time encoding and the best code rate. Image quality.
(2.2) Automatic content implantation

The issue of automatic implantation of advertisements is discussed here. One is to synthesize into the video before encoding, this process has little to do with encoding. But after synthesizing directly into the video, all viewers see the same content.
To be personalized and accurate advertising, it is only synthesized after decoding on the playback side. To do this, the server not only sends the original video stream, but also sends the positioning method and image data of the post-composite object so that the client can dynamically synthesize as needed.
First of all, the advantages of automatically implanted advertisements compared with the previous patches are obvious. The number of ads that can be implanted is very large, the effect is more natural, and users will not have obvious resentment.
Secondly, personalized and accurate delivery further expands the total capacity and efficiency of advertising.
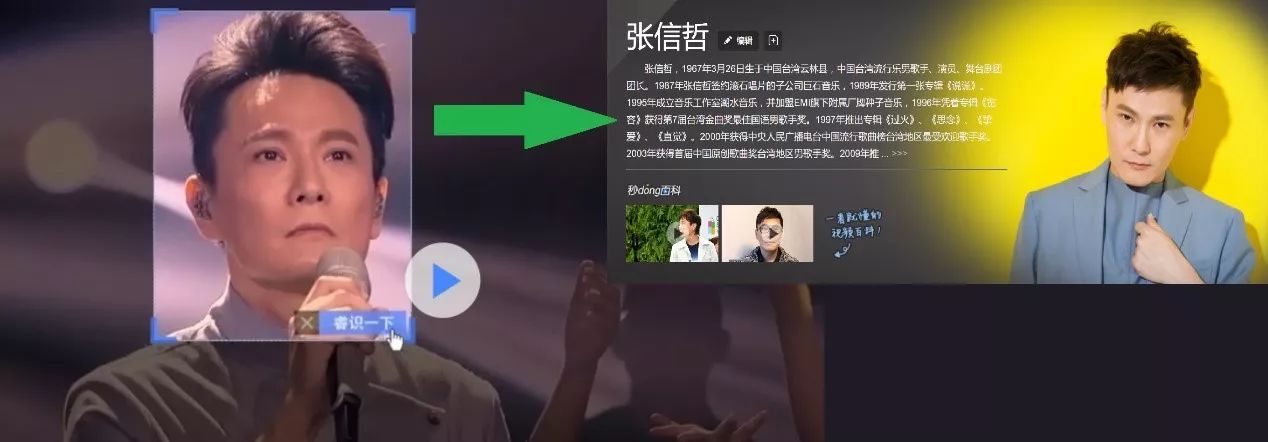
(2.3) Interactive video

The current basic practice is to connect with the search engine after image recognition to generate a content link.
(3) Artificial intelligence enhanced decoder
(3.1) Super resolution of a single image
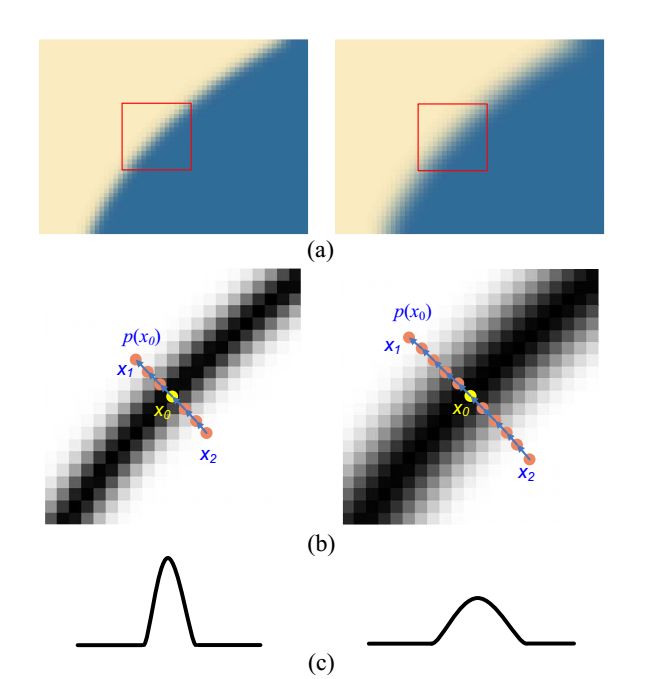
Natural images are basically formed by a combination of flat texture fills and significant edges (lines).
Conventional stretching algorithms have bilinear interpolation and bicubic spline curve differences. In general, the cubic curve is better than the linear interpolation effect.
However, 15 years ago, when I was working as a DVD player in Jinshan, I was studying interlacing technology.
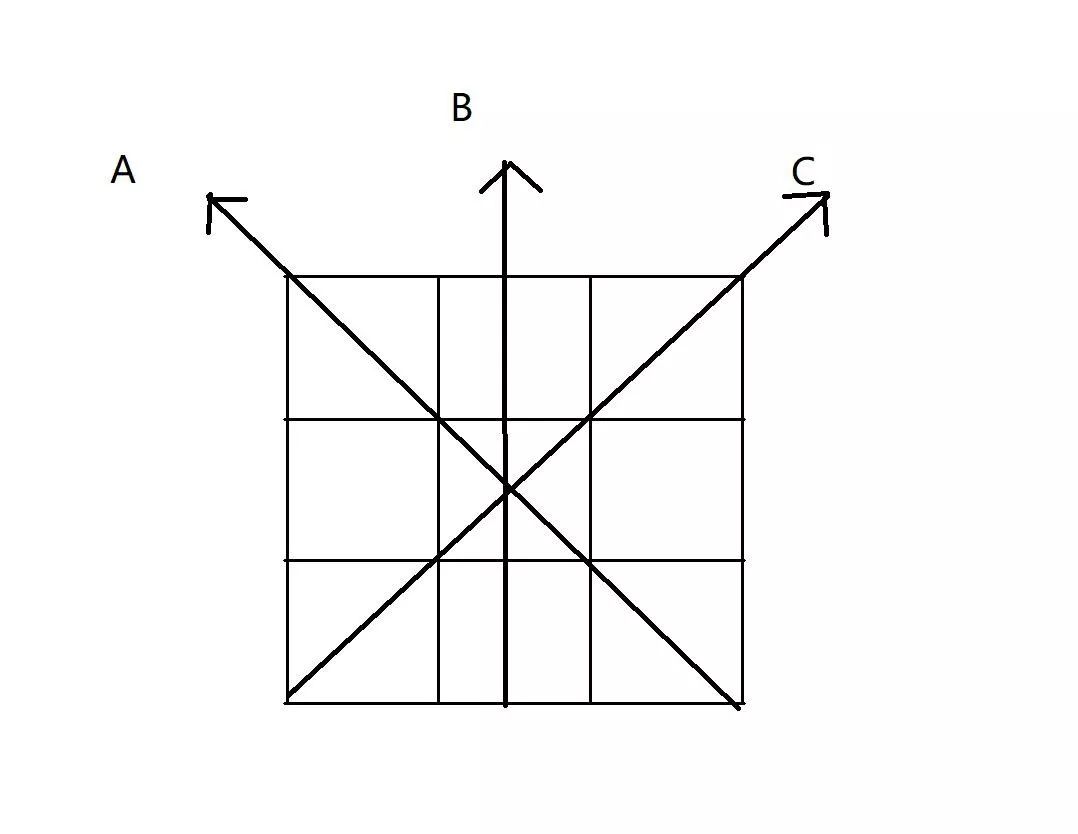
As shown in the figure above, the first row and the third row are the original image data, and the second row is the data to be inserted. A common interpolation method is to make a cubic interpolation in the B direction. But this time I calculated the gradients in the three directions A, B, and C, taking the smallest gradient in the direction, and doing simple linear interpolation on the pixel gradient and the maximum direction.
At this time, I had a surprising discovery that the visual effect of simple bilinear interpolation is better than three curves. Why is this?
The reasons for the image blur are as follows:
Lines become blurred at low resolutions.
Low resolution images introduce additional blur on the line when stretched to high resolution.
The presence of noise.
For the second point we specify: For example, B-spline, the cubic spline has an application condition, that is, the sample data itself should be smooth, at least segmentally smooth. However, in the image, the boundary between the object and the background does not satisfy this condition. Ordinary cubic spline interpolation does not take into account the differences between objects within the image, simply calculating the entire image as a whole. This inevitably introduces a serious blur at the boundary.
Therefore, super resolution is mainly processed from the above aspects. The noise processing technology has matured. Today we will not fight round.
The first discussion point is how to reduce the stretching effect of the line, that is, the sharpness of the line.
For example, a 4x4 pixel block is more common in the following form:

The filter matrix of a common cubic b-spline is:
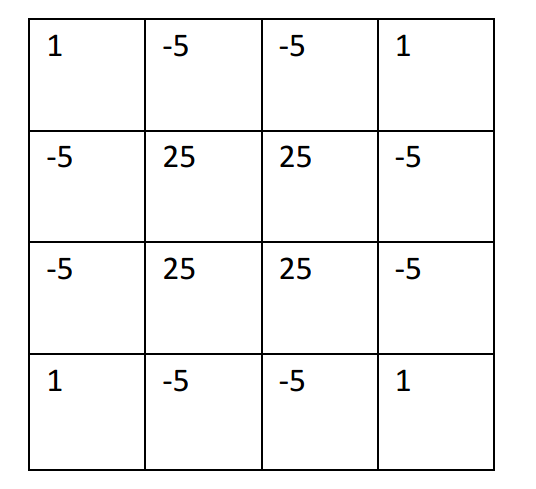
For example, we are going to insert a point in the center of a 4x4 pixel block:
In the first case, the insertion point is on the boundary.

Use standard filters:

Use an improved filter:
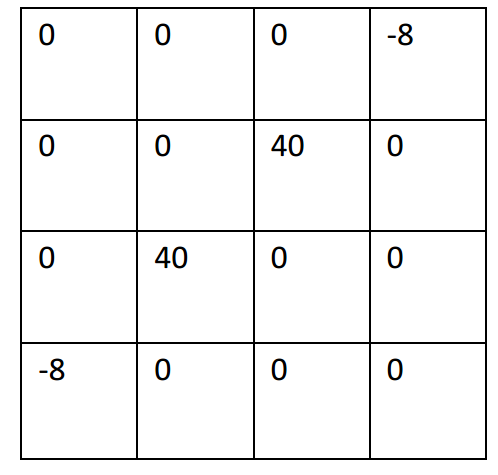

In the second case, the insertion point is within the boundary:

Standard filtering:

The effect is acceptable.
In the third case, the insertion point is outside the boundary:

Use standard filters:

Use an improved filter:

The third case is actually the same as the first one. So we just have to consider the insertion point on the boundary.
Considering that each pixel is actually 8 bits, the possible combination of a 4x4 pixel block is basically a 128-bit integer. This is an extremely huge number. However, in reality, it may be far less than the theoretical upper limit. Basically, considering thousands of combinations is enough. In this case, you need to use statistical methods, or machine learning methods, to obtain a better filter parameter table. This is a very sparse distribution, and you need to design a better hash method to construct and find.
The general machine learning process is similar: prepare some raw HR images (2x2) and LR (1x1) images generated from the samples as paired data. Then several optimization operations were used:
In the first step, the complex 4x4 gradient image lattice is processed into a simple codebook image (HASH).
In the second step, for the codebook image, the B-spline filter parameters are reconstructed by considering the adjacent pixel gradient weights, and the SAD (COST function) calculation is performed each time with the original 2x2 image to find the closest one. Fit the curve parameters (downhill method).
In the third step, the probability distribution is calculated for a large number of parameters obtained in the previous step, and the parameter with the highest probability is taken as the optimal solution of the codebook.
In the fourth step, the approximate codebooks are combined to reduce the number of codebooks.
Another point of discussion is that the low-resolution image blurs the boundary and there is no way to remove it. A method of gradient transformation has been proposed:
The idea of ​​this algorithm is to calculate the distribution of the gradient and then narrow the gradient appropriately. Regardless of the speed of implementation, the effect of this method is also amazing.

The amount of computation of this algorithm is too large. We can only find a way to integrate this process into the process of finding the filter parameter matrix.
In the actual process, we use the super-resolution calculation obtained by the above process. Then we can estimate the approximate computational complexity of such an algorithm: 4x4 matrix registration, lookup filter, and then 16 multiplications per point. The entire process is estimated to be equivalent to 40 multiplication operations. Therefore, with the current cpu performance, fully optimized with avx256/512 or hvx, it is entirely possible to achieve real-time 30fps over 1080p to 4k super resolution.
In this way, the image obtained at some time may even have a visual effect that exceeds the original input image.

(3.2) Super resolution of video
Above is the super resolution of a single image. The super resolution of a video is different from a single image. A single image super-resolution algorithm can be incorporated into the video super-resolution.
The basic idea of ​​video super-resolution is to reconstruct high-resolution images from successive video sequences, involving image registration and sub-pixel extraction. Research methods and evaluation methods are also very different. Some people have some doubts when applying the super-resolution method of images:
First of all, video coding is a lossy compression process. The sequence compression degradation process of different resolutions is different, so the appropriate HR/LR pairing cannot be found. Video quality assessment is also far more complicated than image quality assessment. Therefore, visual quality is a relatively simple evaluation standard. Of course it is ok to look for a HR/LR pair to calculate the PSNR, but the persuasiveness is far less than the image pairing.
Evaluation model:
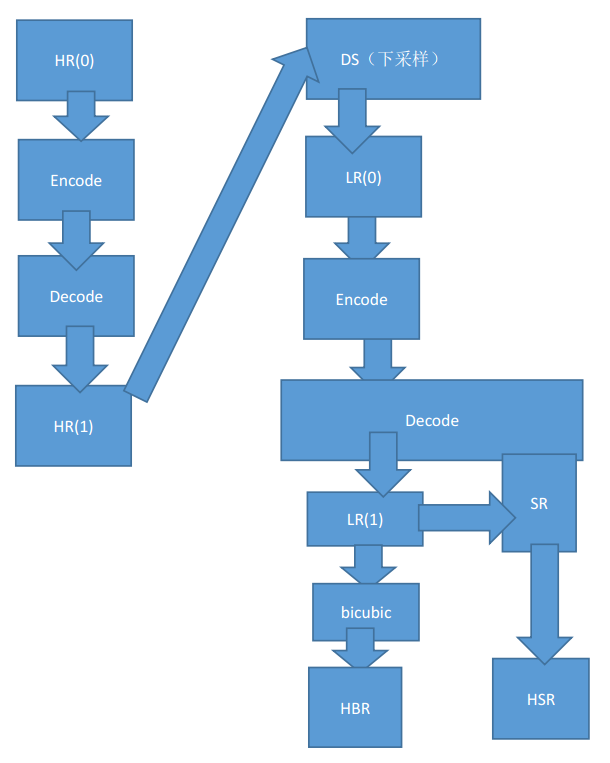
For example, in this process, HR(0) is not suitable for the original resolution reference because the uncompressed video image is huge. We can choose HR(1) and HSR to compare and obtain a PSNR(0), then select HR(1) and HBR obtained by ordinary stretching to obtain a PSNR(1). If PSNR(0) is better than PSNR(1) If it is high, it means that super-resolution has achieved results.
Ordinary video sequence object registration and subpixel extraction are very slow. In order to speed up, we simplify this process, save the registration and spatial prediction process, generate the fractional motion vector with reference to decoding, and complete the sub-pixel extraction of a part of the pixel block directly in the decoding process.
In order to further improve the processing speed, some optimization measures are also adopted here:
The experiment found that in a video playback sequence, if a frame with a slightly lower resolution is added, a relatively high-quality image is added, and compared with the frame-by-frame high-quality image, the human eye does not cause too much difference.
Therefore, in the video SR process, the basic image HBR+ generated by the ordinary b-spline + noise reduction can be used for HSR processing every two frames:
[HSR] , [HBR+] , [HBR+], [HSR], [HBR+], [HBR+], [HSR], [HBR+], [HBR+]
The detailed process of the fast super-resolution process SR above this video can be described as:
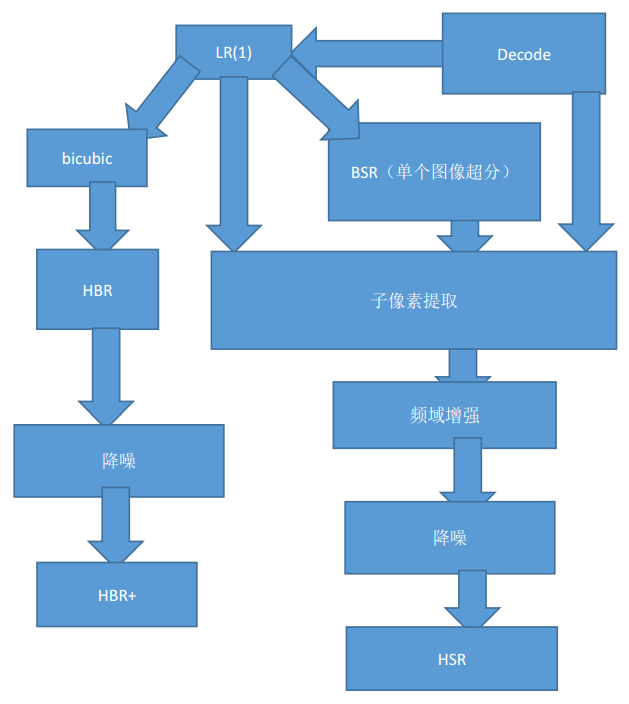
It is estimated that the quality of the HSR video image output by the entire super-resolution process is improved by about 1 dB.
everyone enjoys luck , https://www.eeluck.com