
MP3 (MPEG Audio Layer 3) is an efficient compression technology based on high fidelity. The MP3 audio encoder is complex and has a high compression ratio, but its tone and sound quality can be kept almost complete, so the audio format file is widely used in computers, networks and various electronic devices.
Because MP3 audio decoding is relatively complicated, in order to achieve the requirements of fast decoding within the control cost range, two feasible 16-point DCT algorithms running on the SoC by adding matrix multipliers are proposed to further improve the feasibility of MP3 decoding speed. Program.
1 MP3 decoding process analysisThe process of MP3 decoding is shown in Figure 1. The main processes of decoding include synchronization processing, de-frame header, sideband information, solution scale factor, Huffman decoding, inverse quantization, frequency line reordering, stereo processing, aliasing reconstruction, and improvement. Inverse discrete cosine transform (IMDCT), frequency inversion processing, and offspring synthesis filtering, and finally output raw PCM data.
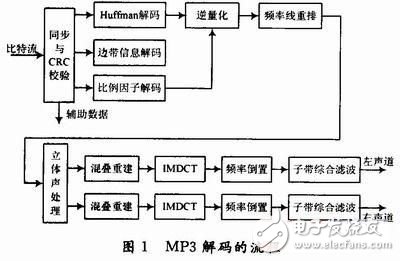
In these processes, the algorithm of IMDCT and sub-band integrated filtering is more complicated, consuming more hardware resources and longer processing time, so the proportion of power consumption is correspondingly higher. Table 1 shows the results of time-consuming analysis of the code after successful porting on the DSP platform.
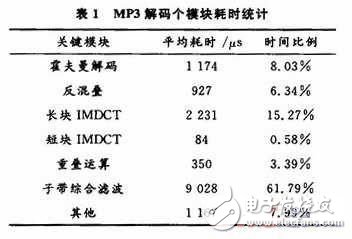
According to Table 1, the sub-band integrated filtering accounts for more than 60% of the total decoding time, which is the most critical module to determine the decoding speed; the second is the long block IMDCT operation, which accounts for more than 10% of the entire decoding time. If the algorithm flow proposed by MPEG-1 is adopted, the numerical calculation mainly focuses on the sub-band integrated filtering. Taking a two-channel 48 kHz sampling rate as an example, the multiplication amount is (48 000/32) & TImes; (64 & TImes; 32 + 512) & TImes; 2 = 7 680 000 times / s. Therefore, sub-band synthesis filtering is the optimization focus of MP3 decoder. Reducing the computational complexity and computation time of sub-band synthesis filtering is the core of MP3 decoder implementation.
2 subband integrated filtering analysisSubband integrated filtering is the last part of MP3 decoding and the most time-consuming key step in the decoding process. It is responsible for restoring the PCM value from the output value of IMDCT, which can be divided into 5 steps. The first is the Matrix operation, ie, 2,...,63. It can be seen from the formula that it takes a value from each subband of 32 subbands Sk to form 32 values ​​into a matrix for operation, and then puts the 64 results of the output Vi into a 1 024 first in first out (FIFO). In the cache, one half of the 1 024 value is taken out to form a 512 vector Ui, and the 512 vector is windowed, that is, Wi=UiDi, i=1, 2,..., 511, and the windowing coefficient Di is officially MP3. Agreement AnnexB Table3-B. 3 available. Finally, the windowing result Wi is superimposed to generate 32 time domain PCM outputs.
The first-order matrix operation multiplication and addition operations are 1,024 times and 992 times, respectively, and 18 matrix operations are required to complete the decoding of one channel. Matrix operations are a key step in subband synthesis filtering. In fact, the method proposed by KonstanTInos Konstantinides can be transformed into a matrix operation by 32-point DCT with only a few changes.
2.1 32-point fast DCT algorithm analysis
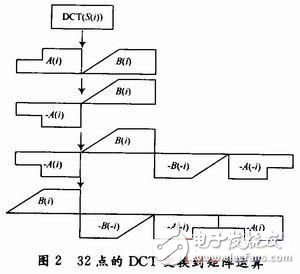
The fast DCT transform algorithm is mainly based on the coefficient matrix splitting method, which increases the preprocessing of the input, so that the multiplication and addition calculations are halved. The 32-point DCT transform to the matrix operation is shown in Figure 2. Where V (1 × 64) represents the output of the matrix, A, B are vectors of length 1 × 16, and (A, B) represents the output of the 32-point DCT.
Since the 32-point DCT can be decomposed into two 16-point DCT transforms, the analogy can be decomposed into 8-point DCT transforms. Considering the finite word length effect in fixed-point digital signal processing, it only needs to be decomposed once, and 32 points. The DCT is converted into two 16-point DCTs. By simplifying the subband filtering process and using the fast DCT transform, the computational complexity of the subband integrated filtering portion can be reduced by approximately 60%.
Decomposed from 32-point DCT to two 16-point DCT processes is derived as follows:
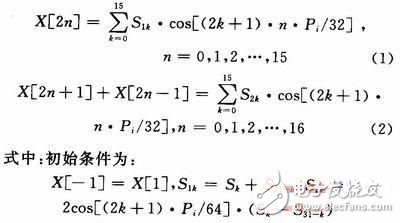
2.2 Fast DCT algorithm optimization based on matrix multiplier
The 3×3 matrix multiplier consists of a flip-flop and a multiply accumulator. It is an important component of a high-performance DSP processor and the core of real-time processing. Its speed directly affects the speed of the DSP processor. There are many implementations of matrix multipliers, basically based on the principle of parallel computing. Since the results of each column are not related to other columns, the multi-column multi-column can be calculated simultaneously by adding multipliers, and the final result can be obtained after n times multiply and accumulate. Figure 3 shows the structure of a matrix multiplier.
Obviously,
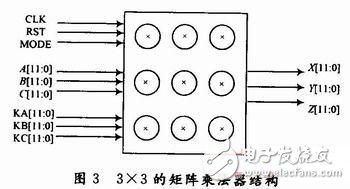
This kind of structure is very fast, but the use of multipliers increases rapidly due to the increase in the matrix dimension n, and there are many triggers used. In many cases, as long as the processing speed is met, there is no need to waste so many hardware resources. Instead, as long as one multiply and accumulate unit is used for pipeline operations, the results of each column can be calculated step by step. When doing the multiply and accumulate one element, prepare the next set of data to participate in the operation. In this way, the higher processing speed can also be obtained.
In this design, since the B matrix is ​​1×n one-dimensional vector input data, the A matrix is ​​a DCT coefficient matrix, and the elements in the A matrix are a linear combination of n coefficients, so the entire matrix multiplier requires 2 sets of n triggers. The device stores input data and n coefficients, and 1 multiply accumulate unit. Input data X[0:n], loop from X[O] to X[n] n times into the multiplier, select the coefficient C[0:n] using the selection signal Assi-gn[0:n], and the coefficient symbol is Sign signal software control, the basic structure shown in Figure 4.
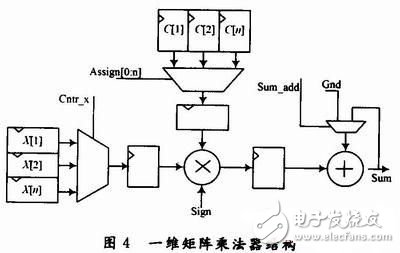
Since the DCT calculation is essentially an n×n matrix multiplication operation, the n×n matrix multiplier adds two sets of coefficients C(n) and n of input X(n) respectively storing the coefficient matrix on the basis of the general multiplier. The register is implemented to achieve a multiply-accumulate function of length n, and the last multiplication result is also saved. Among them, the coefficient in the DCT is n linear combinations of a set of n wikis. Only need to input n coefficients once, use software to select and symbol control to achieve these different coefficient combinations, no need to repeatedly set the number in the register, greatly improving the efficiency of the fetch/set, saving the operation time of the entire DCT .
Therefore, in calculating the 32-point DCT, the 32-point DCT can be decomposed into two 16-point DCT calculations, and the calculation amount is also reduced by one time. Two sets of 16x16 matrix multipliers can be used for parallel calculations, resulting in a significant reduction in computation time. Table 2 shows the time required for subband integrated filtering to use different implementations by adding matrix multiplier optimization.
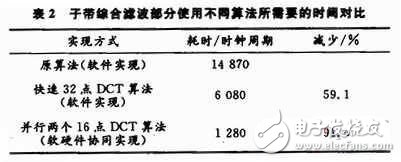
The results show that the use of the fast 32-point DCT algorithm to improve the sub-band synthesis filter calculation is effective in Section 2.1, directly reducing the computation time by 59%. In the parallel two 16 × 16 matrix multipliers to accelerate the calculation of fast 32-point DCT, can achieve significant results: the calculation time is reduced by about 91.4% compared with the original algorithm, and only one multiplier and 30 are added to the hardware. Data latches, as well as partial control circuits. A large increase in the calculation speed of the sub-band integrated filter can be obtained by using the software and hardware cooperative operation.
3 ConclusionThe design is oriented to SoC to speed up the processing speed of sub-band integrated filtering in MP3 decoding based on 32-point fast DCT algorithm by adding matrix multiplier, which greatly alleviates the bottle neck of the system, making the system main frequency lower (fs≤ The 100 MHz) SoC platform makes it possible to decode MP3.
Bluetooth Charger,Wireless Charger,Wireless Speaker Mobile Phone,Portable Charger With Stand,Wireless Bluetooth Charger,10W fast charger for phone
Shenzhen Konchang Electronic Technology Co.,Ltd , https://www.konchangs.com