
This article is an overview of machine learning algorithms, as well as a personal learning summary. By reading this article, you can quickly get a clear understanding of machine learning algorithms. This article promises that there will be no mathematical formulas and derivations, which is suitable for easy reading after a meal, hoping to make the readers get a little more useful stuff.
This paper is divided into three parts. The first part is the introduction of anomaly detection algorithm. Personally, this kind of algorithm is very useful for monitoring system; the second part is the introduction of several common algorithms for machine learning; the third part is depth. Introduction to learning and reinforcement learning. Finally there will be a summary of my own.
1 anomaly detection algorithmAnomaly detection, as its name implies, is an algorithm for detecting anomalies, such as network quality anomalies, abnormal user access behavior, server anomalies, switch exceptions, and system anomalies, etc., which can be monitored by an anomaly detection algorithm. Personally, this algorithm is worthy of our evaluation. Do the monitoring to learn from the reference, so I will introduce the content of this part separately.
Anomalies are defined as "more likely to be separated" - can be understood as points that are sparsely distributed and farther away from a dense group. Statistically, in the data space, the sparsely distributed regions indicate that the probability of data occurring in this region is very low, so the data falling in these regions can be considered abnormal.
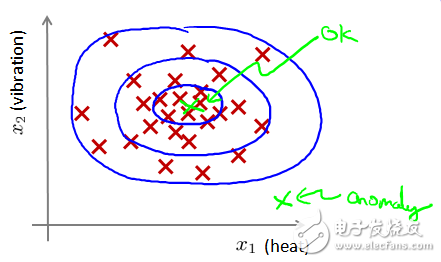
Figure 1-1 shows that the outliers are far away from the normal point of high density.
As shown in Figure 1-1, the data in the blue circle is more likely to belong to the group of data, and the more remote the data, the lower the probability that it belongs to the group of data.
The following is an introduction to several anomaly detection algorithms.
1.1 Distance-based anomaly detection algorithm
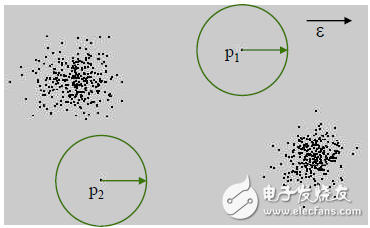
Figure 1-2 Distance-based anomaly detection
Thought: One point If there are not many small partners around, then you can think that this is an abnormal point.
Step: Given a radius r, calculate the ratio of the number of points in the circle centered on the current point and the radius r to the total number. If the ratio is less than a threshold, then this can be considered an anomaly.
1.2 Depth-based anomaly detection algorithm
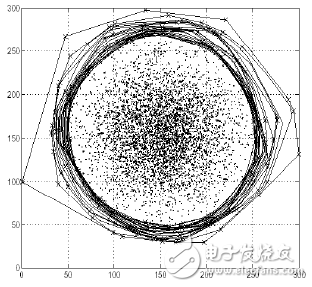
Figure 1-3 Depth-based anomaly detection algorithm
Thought: Anomalous points are far away from dense groups, often at the very edge of the group.
Step: By connecting the outermost points and indicating that the layer has a depth value of 1; then connecting the points of the outer outer layer to indicate that the depth value of the layer is 2, and repeating the above actions. It can be considered that the depth value is smaller than a certain value k as an abnormal point because they are the points farthest from the center group.
1.3 Distribution-based anomaly detection algorithm
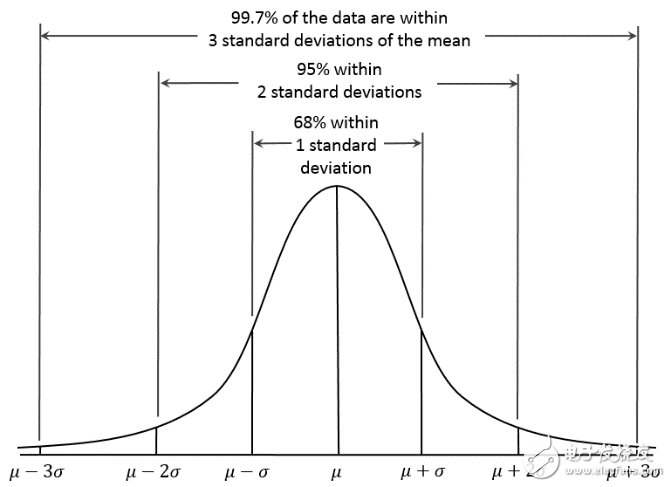
Figure 1-4 Gaussian distribution
Thought: When the current data point deviates from the average of the overall data by 3 standard deviations, it can be considered as an abnormal point (how many standard deviations can be adjusted according to the actual situation).
Step: Calculate the mean and standard deviation of the existing data. When the new data point deviates from the mean of 3 standard deviations, it is considered an abnormal point.
1.4 Partition-based anomaly detection algorithm
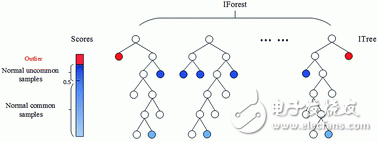
Figure 1-5 isolated deep forest
Thought: The data is continuously divided by an attribute, and the abnormal points can usually be divided into one side very early, that is, isolated early. The normal point, because of the large number of groups, needs to be divided more times.
Step: construct a plurality of isolated trees by randomly selecting an attribute of the data at the current node, and randomly selecting a value of the attribute to divide all data in the current node into two left and right leaf nodes; if the leaf node has a small depth or There are still many data points in the leaf node, and the above division continues. The anomaly point is expressed as the depth of the tree that is on average low in all isolated trees, as shown by red in Figure 1-5 as an anomaly with a very low depth.
Motion Control Sensor is an original part that converts the change of non-electricity (such as speed, pressure) into electric quantity. According to the converted non-electricity, it can be divided into pressure sensor, speed sensor, temperature sensor, etc. It is a measurement, control instrument and Parts and accessories of equipment.
Incremental Rotary Encoder,Incremental Optical Encoder,Incremental Shaft Encoder,Absolute And Incremental Encoder
Changchun Guangxing Sensing Technology Co.LTD , https://www.gx-encoder.com