
This paper summarizes several MapReduce patterns and algorithms commonly found on the web or in the paper, and systematically explains the differences between these technologies. All descriptive text and code use the standard Hadoop MapReduce model, including Mappers, Reduces, Combiners, ParTITIoners, and sorTIng. The detailed analysis is as follows.
Counting and summing
Problem Statement: There are many documents, each of which has some fields. You need to calculate the number of occurrences of each field in all documents or what other statistics for those fields. For example, given a log file, each of these records contains a response time, and the average response time needs to be calculated.
solution:
Let's start with a simple example. In the following code snippet, Mapper counts the frequency every time it encounters a specified word. The Reducer traverses the collection of these words one by one and then adds their frequencies.
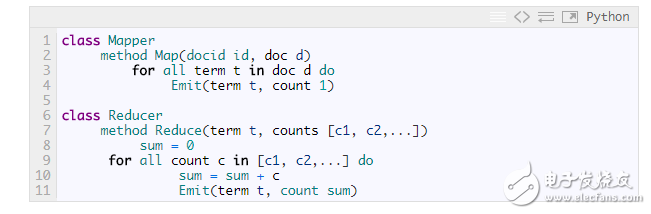
The shortcomings of this approach are obvious, and Mapper submits too many meaningless counts. It is possible to reduce the amount of data passed to the Reducer by first counting the words in each document:
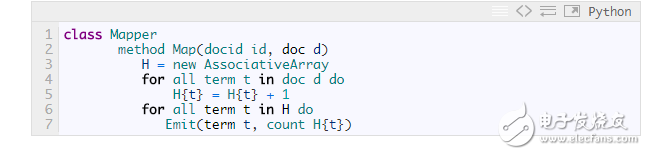
If you want to accumulate more than just the contents of a single document, but also include all the documents processed by a Mapper node, then you need to use Combiner:
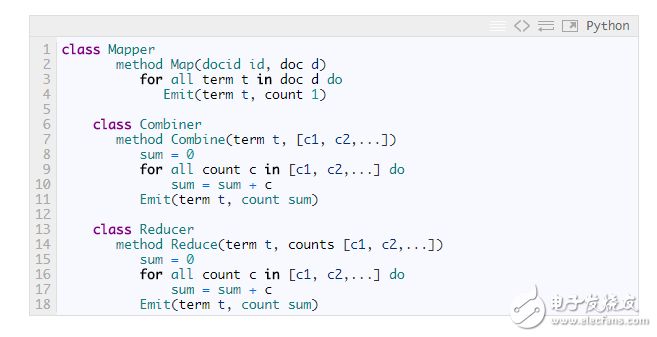
application:
Log analysis, data query
Sorting and sorting
Problem statement:
There are a series of entries, each with several attributes, to save entries with the same attribute value in a file, or to group entries by attribute value. The most typical application is the inverted index.
solution:
The solution is simple. In Mapper, the required attribute value of each entry is used as the key, which itself is passed as a value to the Reducer. The Reducer takes an entry grouped by attribute value, which can then be processed or saved. If you are building an inverted index, then each entry is equivalent to a word and the attribute value is the document ID where the word is located.
application:
Inverted index, ETL
Filter (text lookup), parsing and verifying
Problem statement:
Suppose there are a lot of records, you need to find all the records that satisfy a certain condition, or transfer each record to another form (the conversion operation is independent of each record, that is, the operation and other records of one record) Not relevant). Text parsing, specific value extraction, and format conversion are all examples of the latter use case.
solution:
Very simple, operate one by one in the Mapper, output the required value or the converted form.
application:
Log analysis, data query, ETL, data verification
Distributed task execution
Problem statement:
Large calculations can be broken down into multiple parts and then combined to compile the results of each calculation to obtain the final result.
Solution: Divide the data into multiple copies as input to each Mapper. Each Mapper processes a single piece of data, performs the same operations, and produces the results. The Reducer combines the results of multiple Mapper into one.
Case Study: Digital Communication System Simulation
Digital communication simulation software like WiMAX transmits a large amount of random data through a system model and then calculates the probability of errors in transmission. Each Mapper processes the data of the sample 1/N, calculates the error rate of this part of the data, and then calculates the average error rate in the Reducer.
application:
Engineering simulation, digital analysis, performance testing
Sort
Problem statement:
There are many records that need to sort all the records or process the records in order according to certain rules.
Solution: Simple sorting is fine – Mappers takes the property values ​​to be sorted as keys and the entire record as a value output. However, the ordering in the actual application is more subtle, which is why it is called the MapReduce core ("core" is sorting? Because the experiment to prove Hadoop computing power is big data sorting? Or Hadoop processing Sorting the keys?). In practice, key combinations are commonly used to achieve secondary ordering and grouping.
MapReduce was initially only able to sort keys, but there are also technical uses that can take advantage of Hadoop's features to achieve sorting by value. If you want to know, you can read this blog.
According to the BigTable concept, it is more beneficial to use MapReduce to sort the initial data rather than the intermediate data, that is, to maintain the orderly state of the data. This must be noted. In other words, sorting once at the time of data insertion is more efficient than sorting each time the number of data is queried.
application:
ETL, data analysis
Logic Gates And Inverters,Circuit Logic Gates And Inverters,Logic Chip Gates And Inverters,Gates And Inverters Logic Output
Shenzhen Kaixuanye Technology Co., Ltd. , https://www.iconlinekxys.com